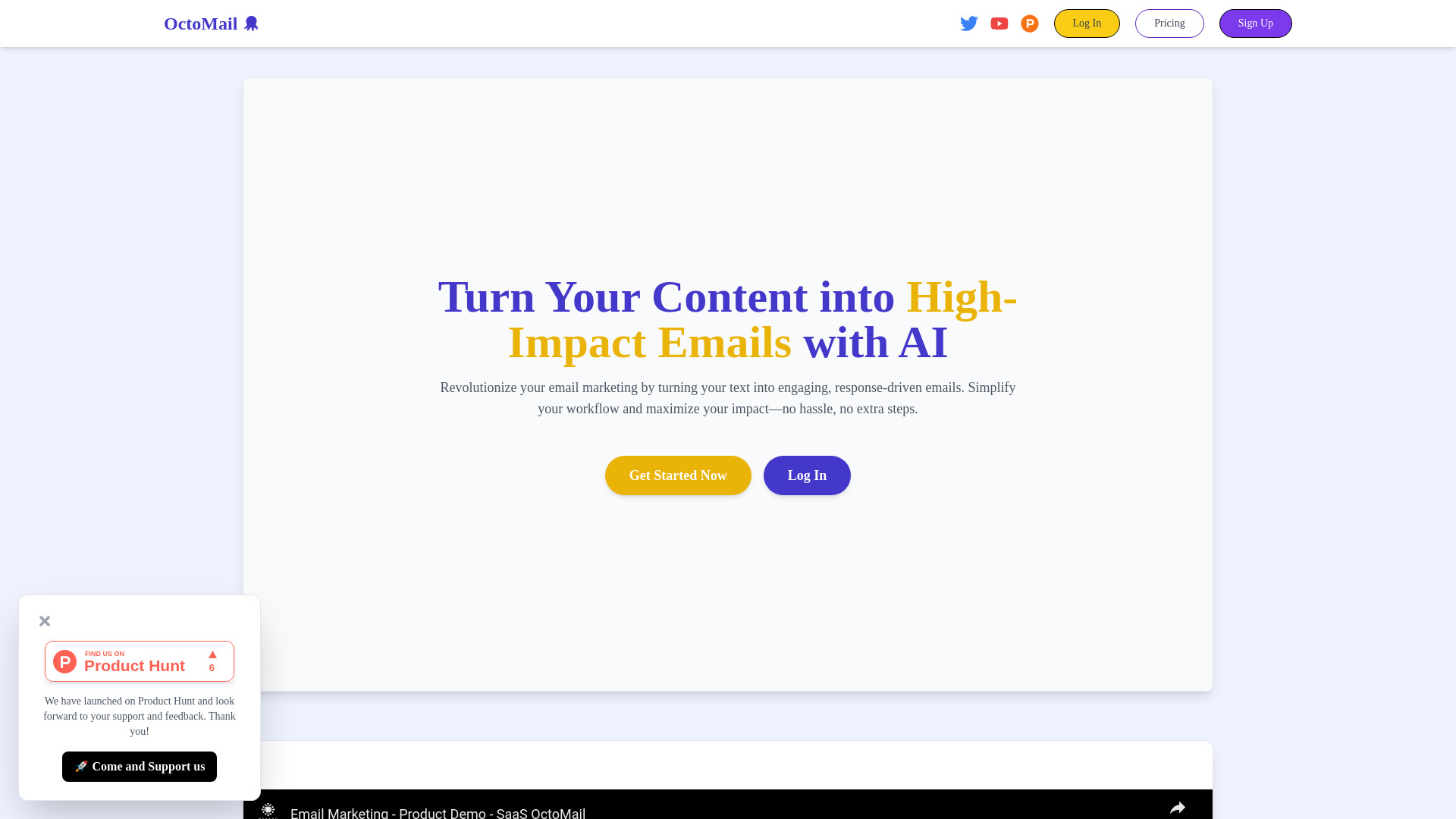
Scispace
创新的学术搜索工具
webml-image-captioning是一个基于深度学习的图像描述生成技术,其目标是通过自动生成自然语言来描述输入的图像。这种技术结合了计算机视觉与自然语言处理两大领域,使得机器能够理解图像中的视觉内容,并将其转化为人类可理解的文本描述。
webml-image-captioning的主要功能是为输入的图像生成自然语言描述。这包括提取图像中的视觉特征,如物体、场景、颜色、纹理等,然后利用自然语言处理技术将这些特征转化为连贯、有意义的文本描述。
1. 跨领域融合:结合了计算机视觉和自然语言处理两大领域的技术,实现了图像与文本之间的转换。
2. 深度学习模型:采用深度学习模型,如卷积神经网络(CNN)用于图像特征提取,循环神经网络(RNN)或转换器(Transformer)用于文本生成,提高了描述的准确性和丰富性。
3. 注意力机制:通过注意力机制,模型能够在生成每个词时专注于图像的不同区域,从而生成更加精细和准确的描述。
4. 多模态信息融合:能够处理图像中的视觉信息和文本中的语义信息,实现多模态信息的有效融合。
webml-image-captioning适用于对图像描述生成感兴趣的开发者和研究人员,以及需要自动生成图像描述的应用场景,如新闻编辑、辅助视觉障碍人士、社交媒体内容生成等。
由于“webml-image-captioning”并非一个广泛认知的特定项目或产品名称,因此无法直接提供其使用常见问题。但一般来说,图像描述生成技术在使用过程中可能会遇到以下问题:
1. 模型训练与数据依赖:模型的性能高度依赖于训练数据的质量和数量。如果训练数据不足或存在噪声,可能会影响模型的准确性和泛化能力。
2. 实时性挑战:图像描述生成任务需要处理大量的视觉和语言信息,因此可能消耗大量的计算资源。对于实时性要求较高的应用场景,需要优化算法和硬件资源以满足需求。
3. 多模态信息融合难题:尽管图像描述生成技术已经取得了显著进展,但如何在复杂场景下有效融合图像和文本信息仍然是一个挑战。
针对这些问题,开发者可以采取以下措施:
使用更大规模、更高质量的训练数据来提高模型性能。
优化算法结构,如采用更高效的深度学习框架和模型压缩技术来降低计算资源消耗。
探索新的多模态信息融合方法,如引入图结构或注意力机制等来提高模型对复杂场景的理解能力。
请注意,由于“webml-image-captioning”并非一个具体的产品或项目名称,因此上述回答基于一般性的图像描述生成技术进行了阐述。如果“webml-image-captioning”是某个特定项目或产品的名称,建议直接查阅该项目的官方文档或社区论坛以获取更详细的信息。